Anthropic Ships Claude Opus 4.8: Dynamic Workflows Spawn Hundreds of Parallel Subagents, and It’s the “Most Honest” Claude Yet
Anthropic released Claude Opus 4.8 on May 28, 41 days after 4.7 — adding Dynamic Workflows that plan and run hundreds of parallel subagents per session, a user-facing effort dial, a 2.5× faster fast mode at 3× lower cost, and its “most honest” self-review behavior yet, at 4.7’s price.
Anthropic released Claude Opus 4.8 on May 28 — just 41 days after Opus 4.7 — and led with a feature, not a benchmark: Dynamic Workflows, a research preview that lets Claude plan a job, spin up hundreds of parallel subagents in a single session, and verify their outputs before reporting back. Anthropic says the workflow can carry out codebase-scale migrations across hundreds of thousands of lines of code “from kickoff to merge, with the existing test suite as its bar.” The model is available everywhere today at the same price as 4.7, via the API id claude-opus-4-8.
The second headline is a knob. Opus 4.8 ships a user-facing effort control on claude.ai and across plans: turn it up and Claude thinks longer and harder for better answers; turn it down and it prioritizes speed and lighter rate-limit consumption. Paired with that is a revamped fast mode that runs at 2.5× the speed of standard and is now three times cheaper than the previous generation’s fast tier — Anthropic’s answer to the latency-and-cost pressure coming from OpenAI’s Codex and Google’s Gemini Flash line.
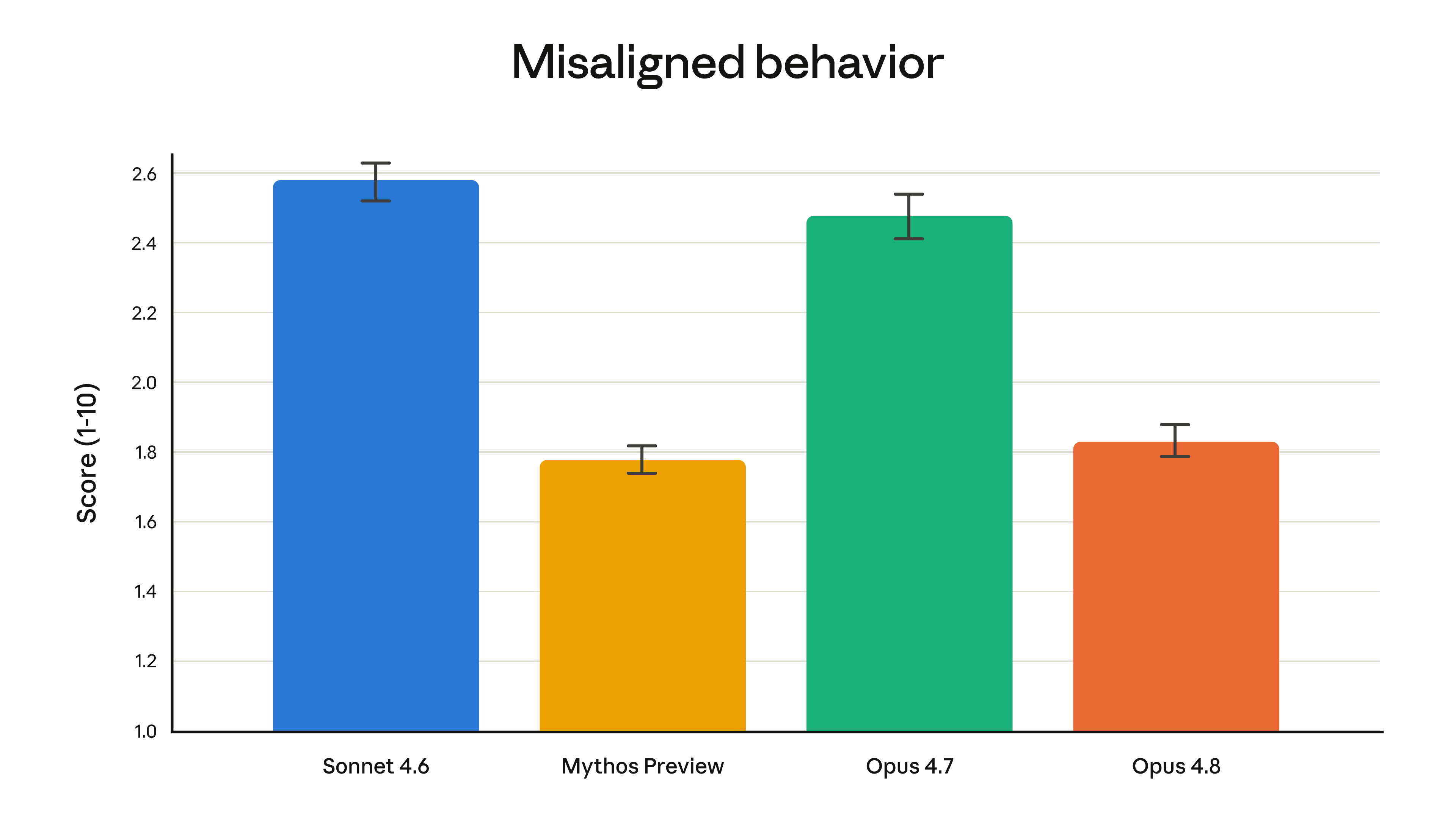
Anthropic’s sharpest marketing claim is about honesty. It calls Opus 4.8 its “most honest” model yet, saying it is roughly four times less likely than 4.7 to let flaws in code it wrote pass unremarked, and more willing to flag uncertainty rather than assert unsupported claims. Bridgewater Associates, an early tester, singled out exactly that trait — “Opus 4.8’s tendency to proactively flag issues with the inputs and outputs of an analysis” — as the upgrade’s most meaningful difference, which matters more for a model you point at a legal brief or a financial model than another point on a coding leaderboard.
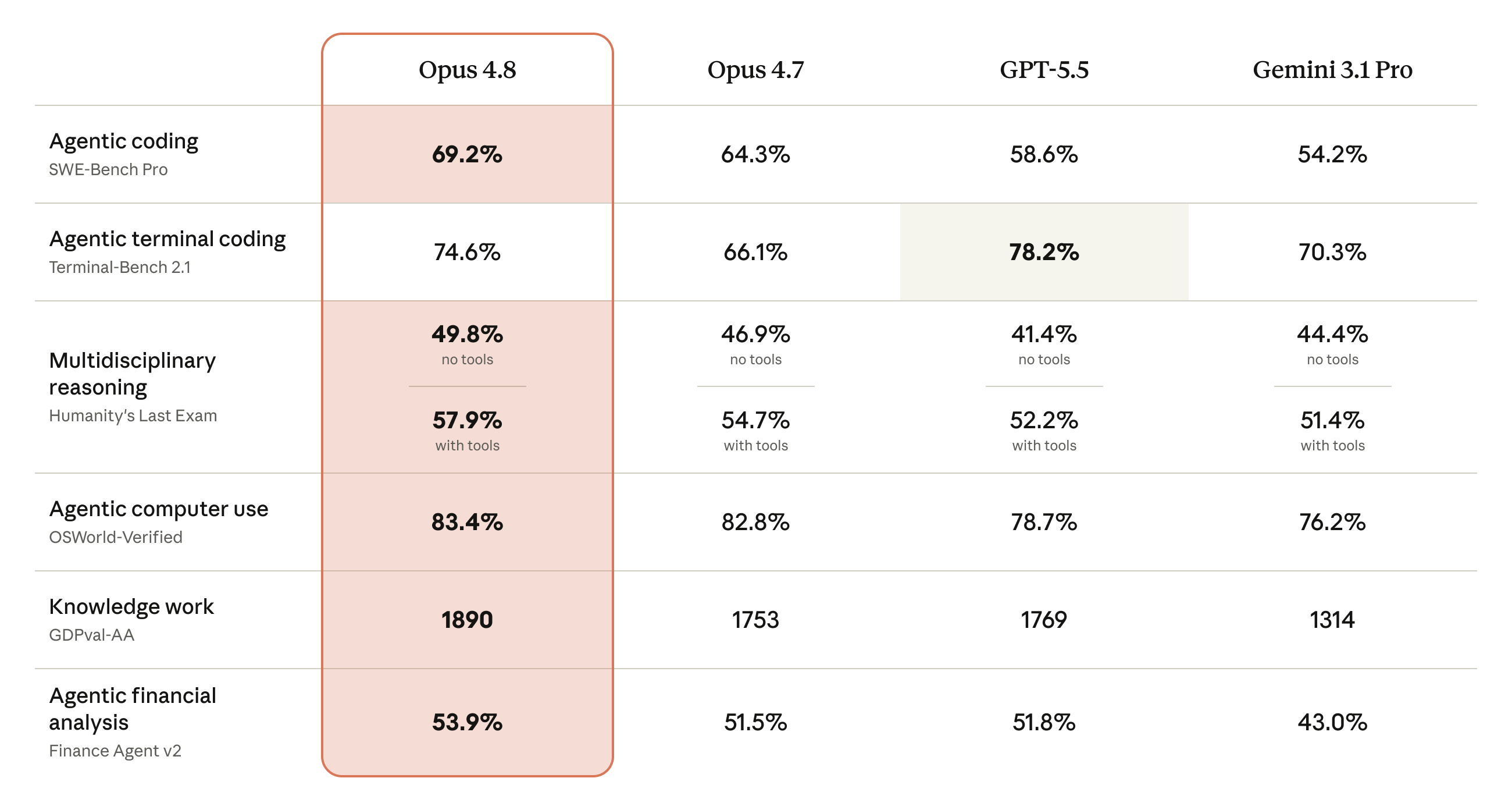
The leaderboard moved anyway. On SWE-Bench Pro agentic coding, Opus 4.8 scores 69.2% — up from 64.3% for 4.7, and ahead of GPT-5.5 (58.6%) and Gemini 3.1 Pro (54.2%). On agentic computer use (OSWorld-Verified) it reaches 83.4%, nudging past 4.7’s 82.8% and comfortably clear of GPT-5.5 (78.7%) and Gemini 3.1 Pro (76.2%). Anthropic also says it posts the highest score yet on its internal Legal Agent Benchmark and is the only model to complete every case end-to-end on its Super-Agent benchmark at cost parity with GPT-5.5.
The release lands inside a louder story. BitsMinds covered the leaked “forbidden-strings” file on May 25 that named Opus 4.8, Sonnet 4.8 and a tier above Opus; today the first of those shipped. Anthropic also teased that its higher-capability Mythos class — held back over cybersecurity concerns — could reach broader availability “in the coming weeks.” All of it arrives with Anthropic reportedly closing a $30B round near a $900B valuation and circling an IPO, which makes a 41-day upgrade cadence look less like routine engineering and more like a company sprinting to set the terms before it prices.
Want AI news before everyone else?
The morning's most important AI stories, straight to your inbox. No fluff.

